Il respeaking è una tecnica di scrittura rapida che permette la trascrizione, la riformulazione o la traduzione di un testo orale simultaneamente alla sua produzione grazie alla tecnologia ASR di riconoscimento automatico del parlato. La tecnologia ASR traduce in parole scritte quanto dettato oralmente a un microfono dal respeaker. Le applicazioni sono molteplici e vanno dalla sottotitolazione intralinguistica e interlinguistica in tempo reale di prodotti televisivi, cinematografici e radiofonici alla trascrizione delle lezioni universitarie e delle conferenze alla verbalizzazione dei processi penali, dei consigli comunali e dei C.d.A.
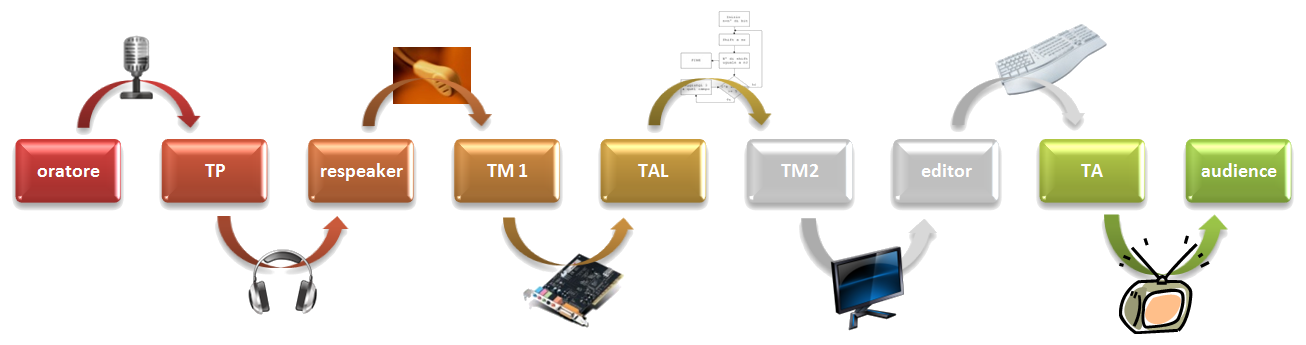
La tecnica del respeaking si distingue da tutte le altre tecniche di sottotitolazione perché prevede la formulazione orale, da parte del respeaker, di un testo "di mezzo" (TM) che sarà poi trascritto dal software TAL (Trattamento Automatico del Linguaggio). Perciò, il respeaker ascolta e guarda il TP, lo riformula, lo traduce o lo ripete oralmente, creando un TM1 per la macchina che, tramite appositi software, elabora e trasforma l’input vocale in sottotitoli elettronici (TM2) da verificare, eventualmente correggere e trasmettere direttamente sugli schermi televisivi (TA). Ovviamente, tutto ciò ha un prezzo: la percezione, la ricezione e la comprensione del TP, l’elaborazione mentale da parte del respeaker per il passaggio dal TP al TM1, l’interazione uomo-macchina, la trasmissione da un software all’altro, la verifica e, infine, l’eventuale correzione della trascrizione e l’invio dei sottotitoli richiedono del tempo che oscilla dai 2 (senza correzione) agli 8 secondi creando un ritardo tra la produzione del TP e la comparsa dei sottotitoli corrispondenti.
Da un punto di vista pratico, il respeaking segue questa procedura:

Il respeaker lavora generalmente in cabine insonorizzate e deve essere pronto a sottotitolare ogni genere di programma a diverse velocità di eloquio e a diversi livelli di tecnicità. Se il programma da sottotitolare dura più di un turno di lavoro (dai 15 ai 40 minuti, dipende dall’esperienza del respeaker e dal genere di programma) o è particolarmente complicato (dibattiti, discussioni parlamentari, ecc.), i respeaker lavorano in coppia, alternandosi o ‘spartendosi’ i locutori. Grazie alle moderne tecnologie, il respeaker ha, inoltre, la possibilità di lavorare in diverse sedi dell’emissione televisiva o addirittura da casa.
Da un punto di vista psico-cognitivo, il respeaking richiede una profonda concentrazione, una grande abilità a lavorare sotto condizioni di duro stress e la giusta determinazione per non arrendersi davanti a risultati inevitabilmente imperfetti. Infatti, il respeaker deve contemporaneamente:
- monitorare continuamente il video per accertarsi che l’eventuale ritardo nella trasmissione del sottotitolo non comprometta la comunicatività del TA. In questo caso, deve rimediare tramite strategie particolari, come l’esplicitazione;
- ascoltare l’audio e capire un testo mai sentito (ci sono casi in cui il respeaker può visionare il programma con un anticipo non sufficiente alla preparazione dei sottotitoli preregistrati) e non sempre prevedibile;
- dettare alla macchina in modo chiaro e riconoscibile un TM1, frutto della riformulazione, ripetizione o traduzione del TP, in vista di un TA pienamente accessibile al pubblico e possibilmente privo di errori;
- controllare ed eventualmente correggere il TM2 prima dell’invio (ciò non è necessario se il respeaker è affiancato da un editor o se l’azienda di sottotitolazione prevede la messa in onda immediata del sottotitolo così come viene riconosciuto dalla macchina);
- trasmettere i sottotitoli (non necessario se è presente l’editor o se si seleziona l’opzione di invio automatico).
Più nello specifico, gli sforzi psico-cognitivi compiuti dal respeaker comprendono:
- la conversione nell’immediato di un testo orale in uno che dovrà essere scritto: i limiti di tempo e le richieste delle associazioni di S/sordi spingono per la realizzazione di sottotitoli verbatim (per quanto riguarda la sottotitolazione intralinguistica). Tuttavia, il passaggio dall’orale allo scritto implica necessariamente un adattamento del testo, tenendo conto degli accorgimenti sopra elencati per la realizzazione di quello che si vorrebbe come prodotto finale. Il tutto continuando a seguire l’eloquio originale, monitorando i video e rispettando i limiti di elaborazione della macchina per non sovraccaricare il sistema;
- il buon utilizzo del software e delle periferiche (microfono, cuffie, tastiera in caso di correzione del testo prima della sua trasmissione, ecc.);
- la regolazione del volume e del tono di voce, una buona pronuncia, un’attenta e chiara articolazione delle parole, la scansione dei confini tra i vari termini, l’utilizzo di brevi pause, ecc. per una buona interazione uomo-macchina;
- l’uso di termini facilmente riconoscibili e il pre-editing di errori che possono essere causati dai limiti del software (omonimi, omofoni, parole simili e/o sconosciute, ecc.);
- il controllo dello stress, della frustrazione per aver fatto un errore e/o aver trovato una soluzione scadente;
- la coordinazione con altre figure professionali, come per esempio l’editor o colleghi respeaker con cui ci si alterna nel lavoro;
- nel respeaking interlinguistico, il passaggio da una lingua all’altra e da una cultura all’altra.
Se a queste attività "di routine" si dovessero aggiungere il continuo controllo del testo trascritto, la correzione degli errori in post-editing, l’invio manuale dei sottotitoli e il controllo del prodotto finale, il carico psico-cognitivo sarebbe enorme e porterebbe a un potenziale aumento degli errori da parte del respeaker. Inoltre, più errori si fanno, più lo stress e la frustrazione per i risultati ottenuti aumentano facendo diminuire la concentrazione e generando ulteriori errori. Per questi motivi si pensa sia necessaria la presenza di un editor.